在网络传输的过程中,拥塞是不可避免的。因为packet switching只负责尽可能的发包,而不去管链路的拥挤情况。如果出现了拥塞则排队中的包会进入Buffer,Buffer满后会丢弃并要求重传,这一是浪费了这个包传输过来所使用的链路资源,二是会进一步加剧拥塞。此时,就需要拥塞控制,来尽可能地避免重传。拥塞控制的设计目标有以下几点:
- 高吞吐量:尽可能高效的利用链路
- 公平性:确保所有flow在进入瓶颈链路时能被公平对待
- 面对变化的网络情况可以快速做出反应
- 分布式控制
TCP的设计思想就是高效的利用链路,在这个思想指导下,TCP连接时丢包重传是必须的,这实际上是一个信号,告诉TCP链路已经到承受能力的极限了,但是要降低重传的概率,这样才能让包高效的被传输到对端。
TCP Congestion Control

TCP的拥塞控制由终端实现,它由观察到的事件来决定如何做出反应(是否丢包),利用滑动窗口来实现流量控制,并试图找出一个能让所有包都正常传输的流速。
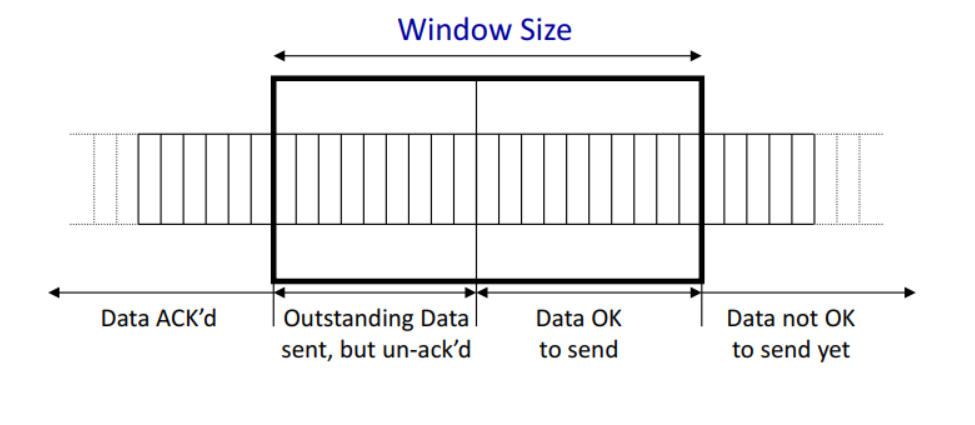

如果一个滑动窗口的长度小于Round-trip time(RTT)那么链路上就会看到一个终端一会发一个包停一会让后再发一个包,这样就不能充分利用链路,一个更好的方式是RTT刚好和滑动窗口的大小一致这样这个窗口的包刚发完就可以发新的包,而TCP的拥塞控制就是在控制这个滑动窗口的大小。

具体的公式是
- 滑动窗口大小 = min(接收者能接收的窗口大小, 拥塞窗口)
接受者能接受的窗口大小是显知的,关键就在于如何确定拥塞窗口的大小
AIMD

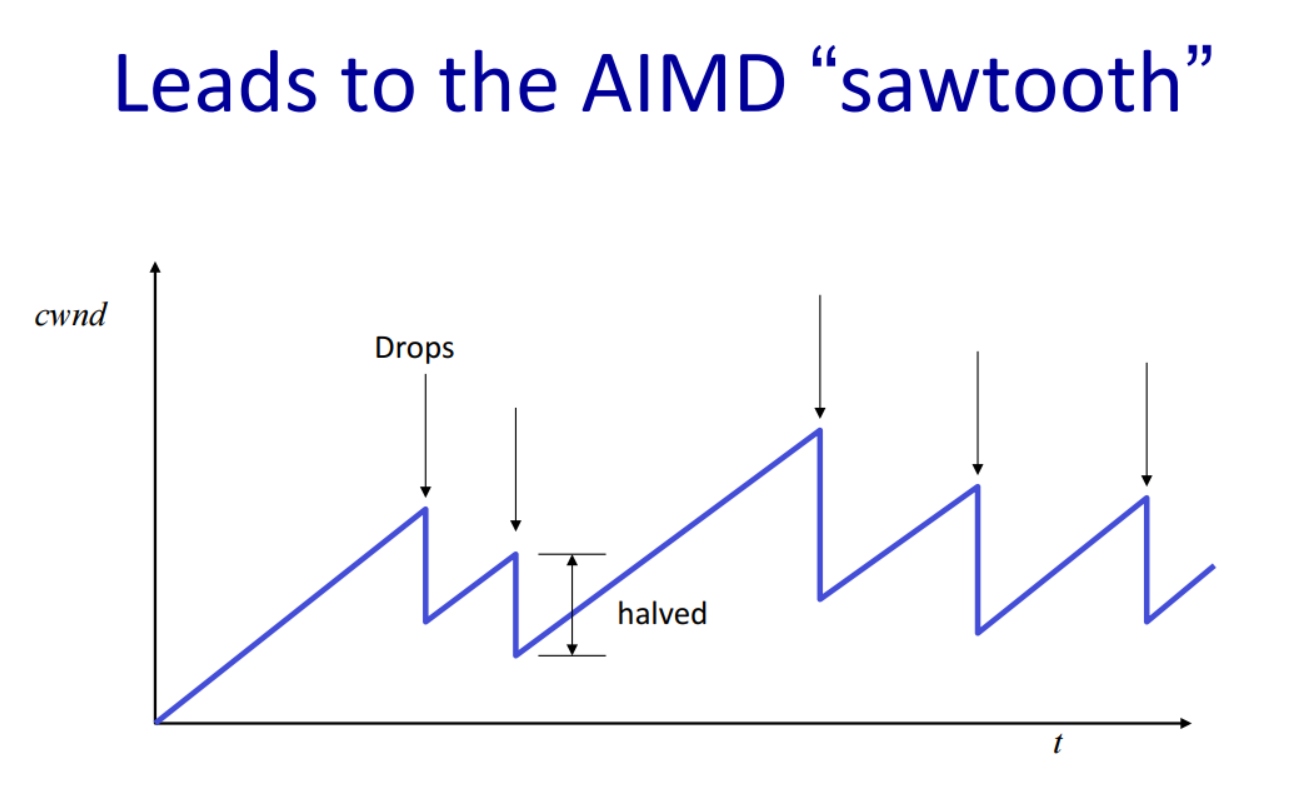
Additive Increase:如果接受者正确的接受了包并返回了ACK,那么就把发送方就把发送窗口的大小加”1”,对于每一个包它将增加1/w,因为有w个数据包,所以增加”1”。
Multiplicative Decrease:丢包的时候返回拥塞信号,发送方的窗口随丢包的数量w来减半。
AIMD with multiple flows
当多路传输时AIMD的情况又有所不同
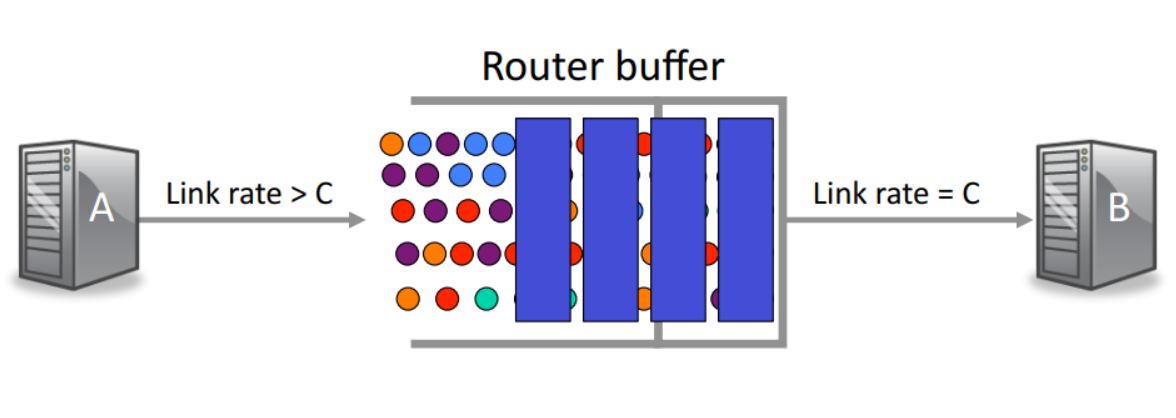
图中每个不同颜色的圆点代表不同来源的包,如果刚好有一个包被丢弃了,那该包的发送方将缩小滑动窗口,从整体上看发送的速率将会稍微下降(因为这是多个源在发送)
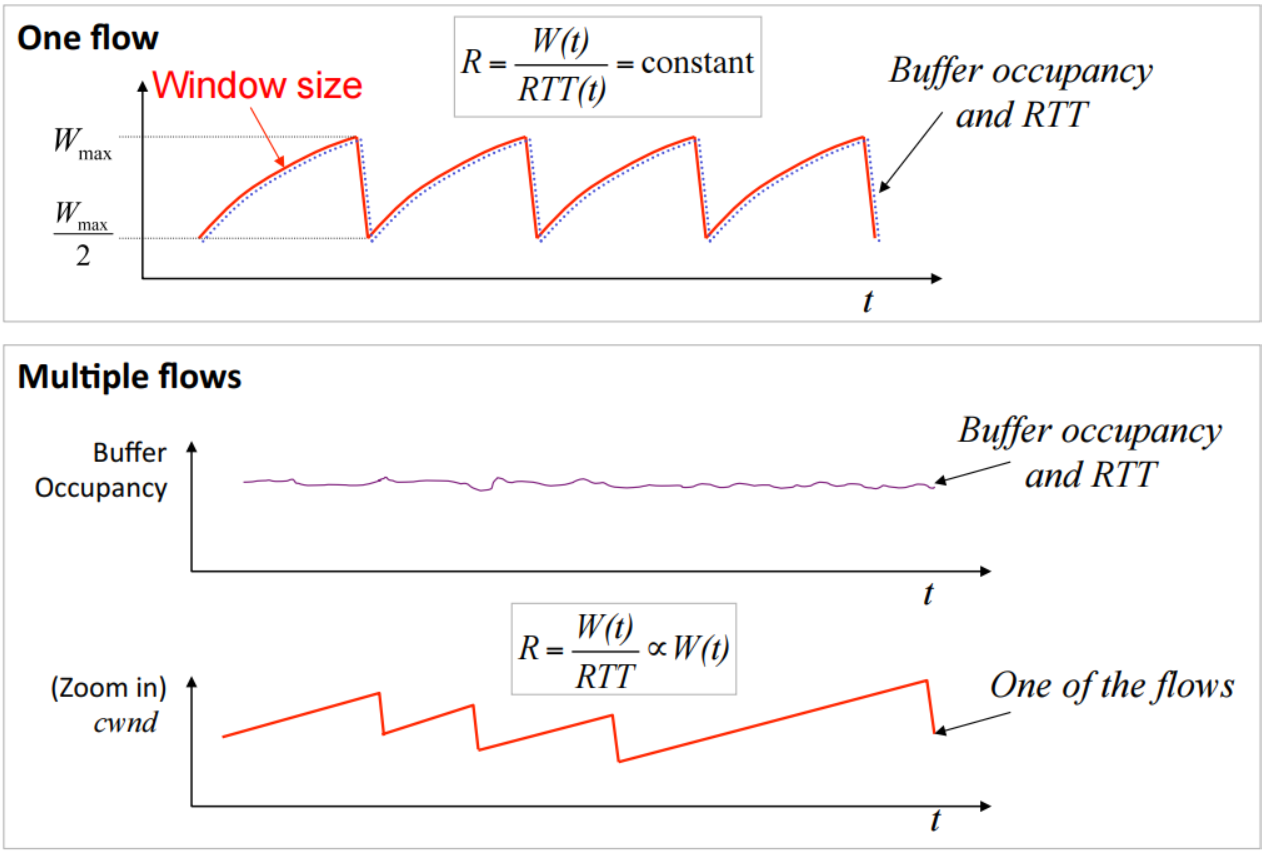
多源的情况下发送速率将是如下公式,p代表丢包概率

从公式中可以看出如果源与目标的RTT很大,那么根据AIMD它的发送速率将很慢,这样被认为是AIMD的一个缺点。
TCP Tahoe

TCP解决了以下三个问题:
- 什么时候传输新数据
- 什么时候去重传
- 什么时候发送ACK
TCP Pre-Tahoe

现代TCP的滑动窗口机制确保了发送方发出的数据不会超过最后一个ACK的数据+窗口大小。而原始的TCP协议是在三次握手之后会根据窗口大小_立刻_发送一个窗口的报文(假如窗口是100KB,它会立刻发送一个100KB的segment)并为每个packet设置定时器,在定时器走完后如果没收到ACK将重传该packet,这样做的问题在于,假设网络所能容纳的packet小于窗口大小,那么发送端发出以后只会有几个被成功接收,它们后面的包将全部被丢弃。
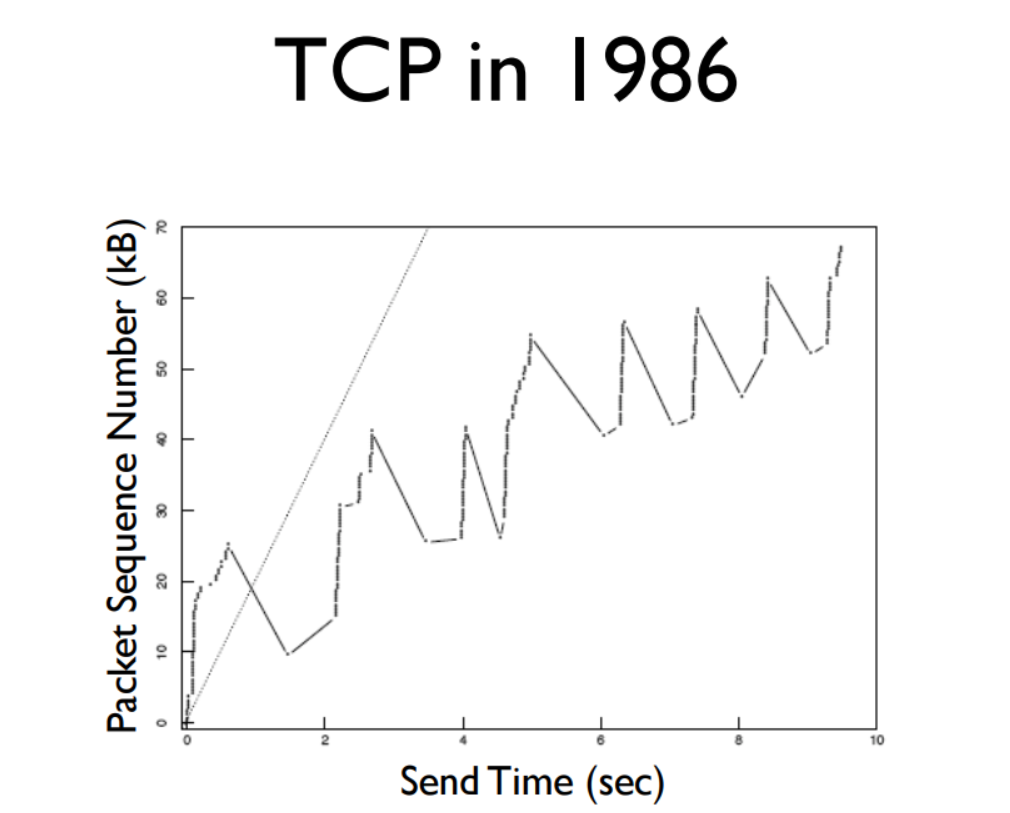
从图中可以看出在发送一些segment后,其他segment就被丢弃了,导致那一个segment的packet都得重传,所以Y的值在不断的上升然后下降。
Improvement of Tahoe


Congestion window
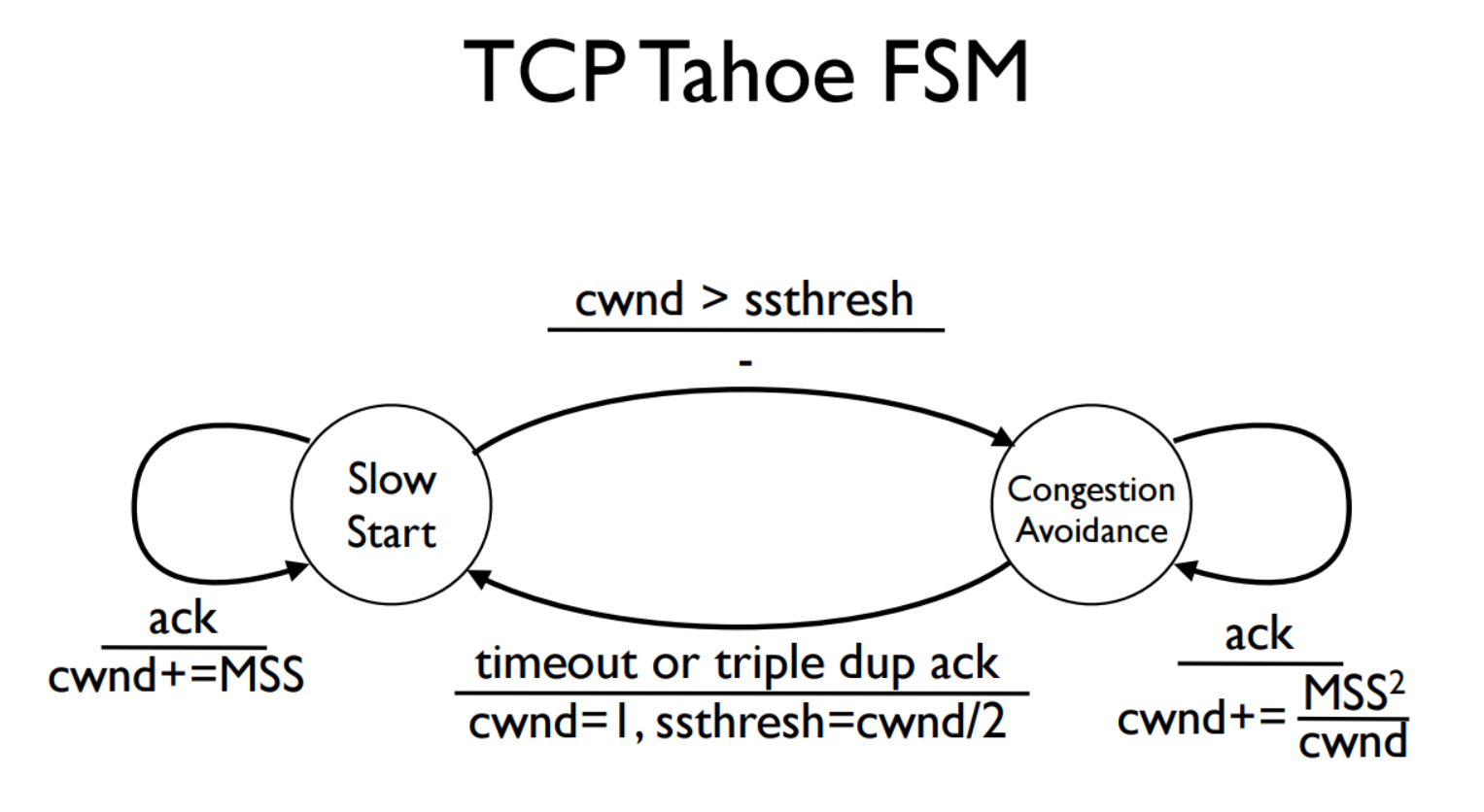
TCP Tahoe预估了拥塞窗口,发送窗口是滑动窗口和拥塞窗口中的较小值,这保证了发送方既不会发送超出接受方处理能力的包,也不会发送超过网络传输能力的包。TCP将测量拥塞窗口的方法分为两个阶段:慢启动与拥塞避免。在稳定状态时,TCP处于拥塞避免状态,遵循AIMD规则。当连接开始增多,或者有包超时时TCP进入慢启动状态,此时不再遵循AIMD规则。
Slow Start

当TCP进入慢启动状态,它的拥塞窗口大小为最大的segment的长度(MSS)或者一个packet的长度,在收到ACK后拥塞窗口会以MSS的倍数增长。这也就意味着拥塞窗口的增长是指数增长,发送方的初始窗口就是MSS那么大,让后发送一个segment,当收到ACK时增加拥塞窗口到两倍的MSS然后发送两倍长的新segment,当再次收到ACK时拥塞窗口变为四倍MSS,同时发送四倍长的segment,也就是如果一切正常发送的segment将会呈现指数级增长。
慢启动这个名字看起来似乎有些误导性,指数增长肯定是比AIMD要快,但是它这个“慢”是和老的TCP发送方式比,也就是该小节开头提到的的直接把整个窗口发送出去相比要更慢。
Congestion avoidance

在拥塞避免阶段,TCP增加窗口大小的速度要慢的多,类似于AIMD,它的增量步长为MSS^2/(每个ACK的拥塞窗口大小)。假设没有包被丢弃,那么TCP的拥塞窗口将在每一个RTT后增加一个MSS的长度,也就是AIMD中的AI。
State Transitions

慢启动让我们可以以一个比较快的速度达到网络的传输能力,当我们接近传输能力的极限时用拥塞避免可以渐进的探查到最终的传输极限。那么这两者又是如何转换的呢?
两种状态的转化依赖三个信号,TCP会累计ACK的数量,当出现重复ACK代表着有些segment丢失了或者延迟,但是其他segment被成功接收,最后如果超时代表出现严重错误。

TCP Reno

TCP Reno 在收到三次重复的ACK(这意味着接收端虽然一直在收到包,但是某个特定的包丢了,发的这三个ACK是那个特定包之后接收到包时发出的)后会采取快速重传机制,不会等到超时时间结束,而是直接重传三次ACK前的那个segment,这种机制使得Reno不会进入slow start状态,只会把拥塞窗口减半,然后维持拥塞避免状态。




